Introduction: Overcoming OCR‘s Long-Document Challenge
The central development is this: Traditional Optical Character Recognition (OCR) models often face significant hurdles when processing lengthy documents. As the volume of generated text increases, these models become progressively slower and more memory-intensive due to the expanding Key-Value (KV) cache. This limitation makes efficient parsing of multi-page files, such as entire books or extensive reports, impractical and resource-heavy.
Table of Contents
- Introduction: Overcoming OCR’s Long-Document Challenge
- What is Unlimited OCR?
- The Core Innovation: Reference Sliding Window Attention (R-SWA)
- Exceptional Performance and Speed
- Training Methodology
- Practical Applications and Use Cases
- Strengths and Considerations
- Expert Perspective
- Frequently Asked Questions
- Strengths:
- Considerations:
- Why does Unlimited OCR matter right now?
- What broader change could Unlimited OCR signal?
- What should the market watch next around Unlimited OCR?
Meanwhile, Baidu has introduced an innovative solution to this persistent problem: Unlimited OCR. This advanced 3-billion-parameter model, which intelligently activates only 500 million parameters during inference, is engineered to maintain consistent performance regardless of document length. Its core innovation lies in a novel attention mechanism that keeps memory and latency flat, marking a significant leap forward in document understanding.
What is Unlimited OCR?
Unlimited OCR is a sophisticated Mixture-of-Experts (MoE) model built upon the foundation of DeepSeek OCR. It leverages the robust DeepEncoder for efficient data compression and an MoE decoder for advanced processing. During inference, despite its 3 billion total parameters, only 500 million are actively engaged, contributing to its efficiency.
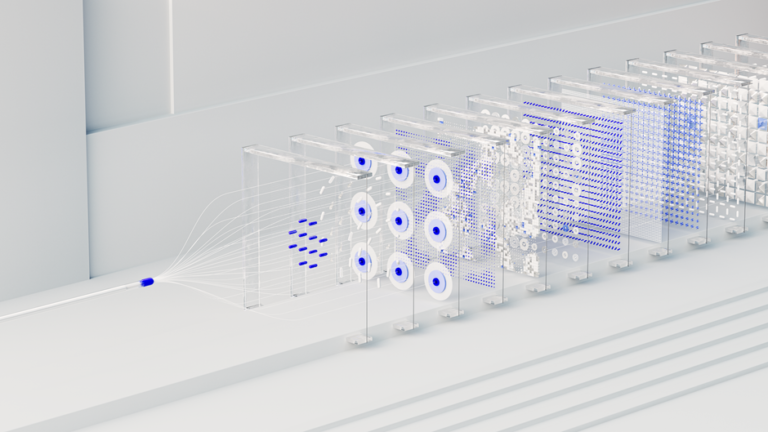
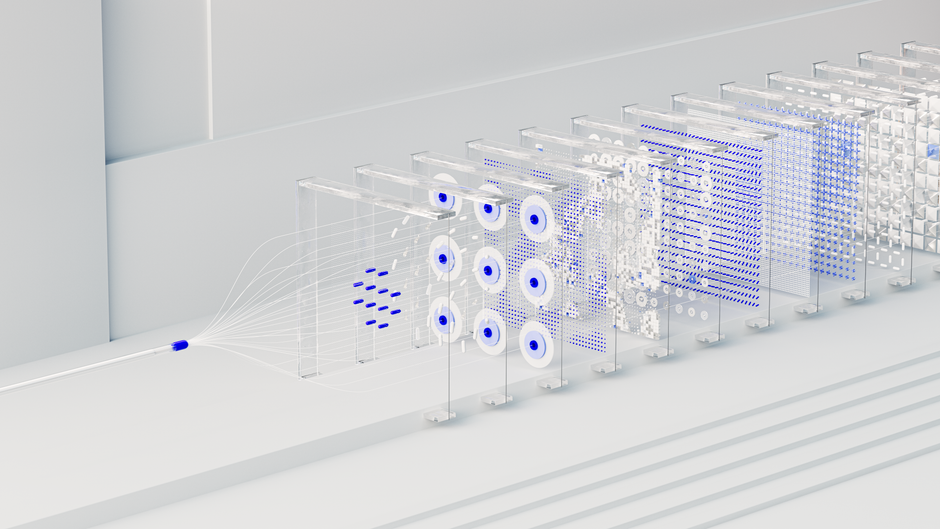
In practical terms, The DeepEncoder acts as a powerful compression engine. It integrates SAM-ViT with window attention and CLIP-ViT with global attention, applying a 16x token compression at the bridge.
This process transforms a high-resolution PDF image (e.g., 1024×1024 pixels) into a mere 256 visual tokens, drastically reducing the initial input size and improving prefill efficiency. Unlimited OCR supports two primary resolution modes: ‘Base’ mode for multi-page documents and ‘Gundam’ mode, which uses dynamic resolution for single-page tasks.
The Core Innovation: Reference Sliding Window Attention (R-SWA)
The fundamental challenge with standard Multi-Head Attention (MHA) in deep learning models is its linear growth of the KV cache with every generated output token. This unbounded growth leads to escalating memory consumption and increased latency, particularly for long sequences.
For example, Unlimited OCR addresses this directly by replacing the decoder’s attention mechanism with Reference Sliding Window Attention (R-SWA). R-SWA breaks the direct link between output length and cache size. Here’s how it works:
- Each newly generated token attends to all reference tokens (which include visual tokens from the input image and any initial prompt).
- Crucially, it only attends to the most recent ‘n’ output tokens (with ‘n’ typically defaulting to 128).
- Tokens older than this ‘n’ window are efficiently evicted from the cache.
This design ensures that the KV cache size remains bounded by a constant value (Lm + n), where Lm represents the reference tokens and ‘n’ is the sliding window width. As the output length (T) grows significantly beyond ‘n’, the memory footprint and per-step latency remain consistently flat. This mechanism is akin to a person transcribing a book: they constantly refer to the original source material but only keep the last few words they’ve written in their immediate working memory, rather than re-reading everything from the beginning.
Exceptional Performance and Speed
That said, Unlimited OCR demonstrates state-of-the-art performance across various benchmarks. On OmniDocBench v1.5, it achieved an impressive overall score of 93.23, surpassing the DeepSeek OCR baseline by a significant 6.22 points. Furthermore, on OmniDocBench v1.6, it reached 93.92 overall, securing the top score in the research paper’s comparisons.
These performance gains are not limited to overall scores; they hold consistently across critical metrics such as text editing, formula recognition (CDM), and table recognition (TEDS). Beyond accuracy, Unlimited OCR also delivers substantial speed improvements. In Base mode on OmniDocBench, it reached 5,580 Tokens Per Second (TPS) compared to DeepSeek OCR’s 4,951 TPS, representing a 12.7% increase. This speed advantage becomes even more pronounced with longer outputs, where Unlimited OCR can be 35% faster than DeepSeek OCR at a 6,000-token output ceiling.
Training Methodology
Interestingly, Rather than being trained from scratch, Unlimited OCR was developed through a process of continue-training from an existing DeepSeek OCR checkpoint. The research team conducted 4,000 training steps, specifically freezing the DeepEncoder and focusing solely on training the decoder.
This process involved approximately 2 million document samples, utilizing 8×16 A800 GPUs. The dataset had a 9:1 split favoring single-page data, with multi-page samples created by concatenating individual pages.
Practical Applications and Use Cases
The constant KV cache and superior performance of Unlimited OCR make it ideal for workloads that traditional page-by-page systems struggle with:
- Whole-Book Transcription: Capable of processing 40+ pages in a single, continuous pass, maintaining high accuracy (edit distance below 0.11) and distinct token retention.
- Comprehensive Document Parsing Pipelines: Efficiently extract text, tables, formulas, and reading order from complex documents in a single forward pass.
- High-Throughput Batch Processing: Designed for robust performance in scenarios requiring concurrent processing of large document batches.
- Broader AI Applications: The Reference Sliding Window Attention (R-SWA) is described as a general parsing attention, suggesting potential future applications in areas like Automatic Speech Recognition (ASR) and machine translation.
However, Developers can integrate Unlimited OCR using minimal code via the Transformers library or for production-level throughput, with SGLang serving an OpenAI-compatible API.
Strengths and Considerations
Strengths:
- Constant KV Cache: Ensures stable memory footprint and latency even with extremely long outputs.
- State-of-the-Art Performance: Achieves top scores on OmniDocBench v1.5 and v1.6 across various metrics.
- Efficient Inference: Only 500 million active parameters keep computational costs low.
- Open Source: Released under an MIT license with open weights, supporting both Transformers and SGLang.
- No Accuracy Compromise: R-SWA delivers gains without sacrificing accuracy on single-page tasks.
Considerations:
- Context Bound: While highly efficient, parsing is not truly ‘unlimited,’ as a 32K context length still imposes a ceiling.
- Prefill Growth: Long prefills still grow with the number of pages, despite significant compression.
- Mode Limitation: Multi-page runs are restricted to ‘Base’ mode, which might occasionally miss very small text elements.
- Future Work: Its applicability to ASR and translation is currently theoretical and not yet a shipped feature.
Baidu’s Unlimited OCR represents a significant breakthrough, offering a powerful and efficient solution for handling the most demanding document parsing tasks.
Expert Perspective
From an industry angle, the clearest signal around Unlimited OCR is how it may influence unlimited. The story reads less like a one-day spike and more like a marker of broader movement.
The next phase will depend on how quickly teams, regulators, or customers react. In practice, that gives Unlimited OCR room to reshape expectations across page over the near term.
For readers focused on practical impact, the best next step is to watch what changes around attention once attention turns into execution.
Frequently Asked Questions
Why does Unlimited OCR matter right now?
Introduction: Overcoming OCR’s Long-Document ChallengeThe central development is this: Traditional Optical Character Recognition (OCR) models often face significant hurdles when processing lengthy documents.
What broader change could Unlimited OCR signal?
As the volume of generated text increases, these models become progressively slower and more memory-intensive due to the expanding Key-Value (KV) cache.
What should the market watch next around Unlimited OCR?
This limitation makes efficient parsing of multi-page files, such as entire books or extensive reports, impractical and resource-heavy.Meanwhile, Baidu has introduced an innovative solution to this persistent problem: Unlimited OCR.